AI-generated
Stable Diffusion
Have questions? Talk to sales













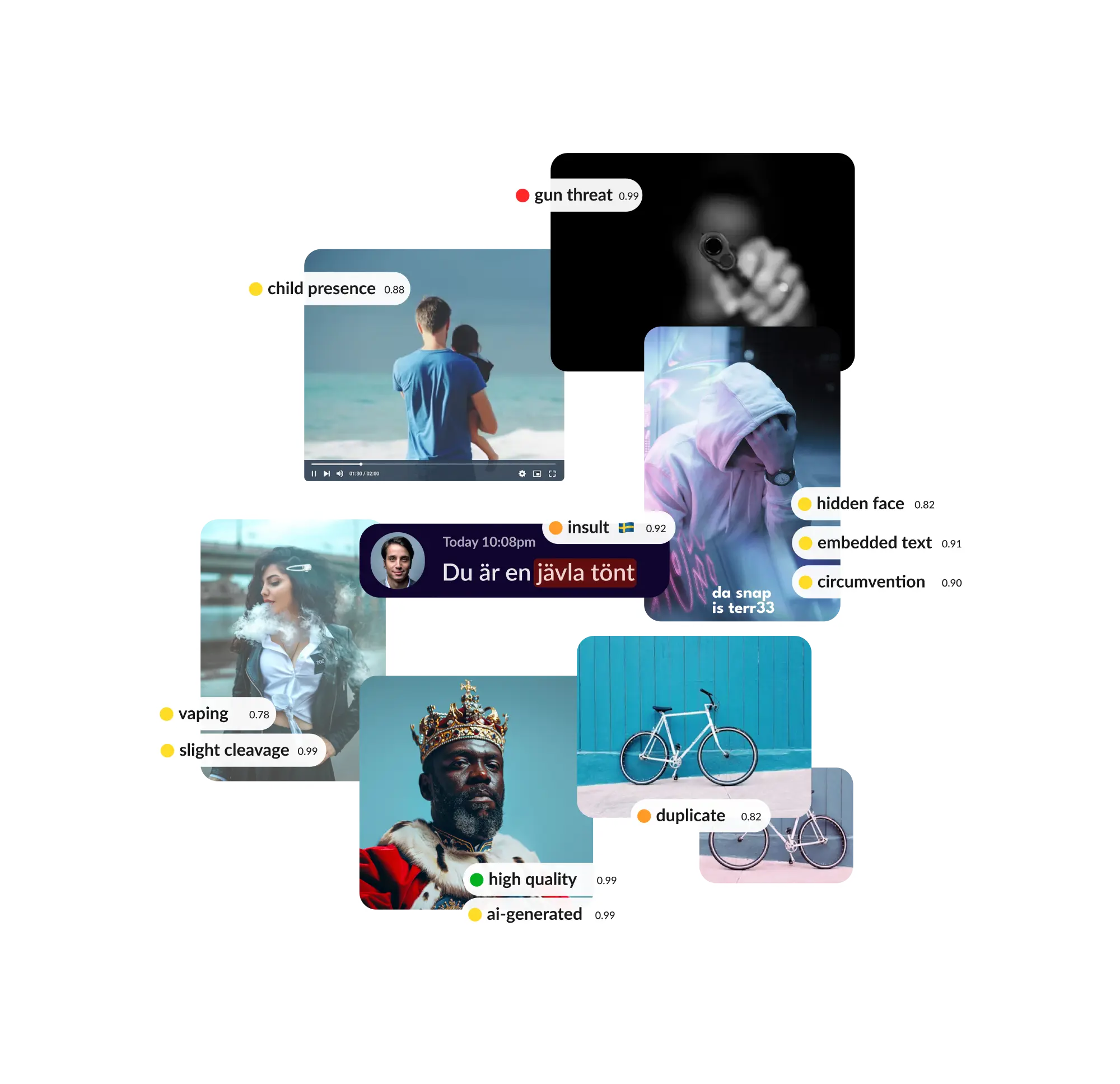
Use 60+ moderation categories across nudity, hate, violence, drugs, weapons, self-harm and more. Context-aware. Highly customizable and fine-tuned to your needs. More accurate than other solutions.
Use Image Moderation Use Video Moderation
Detect sexual, hateful, violent, insulting or otherwise inappropriate texts. Detect personal information, links, usernames. Detect attempts to engage in restricted activities.
Explore Text Moderation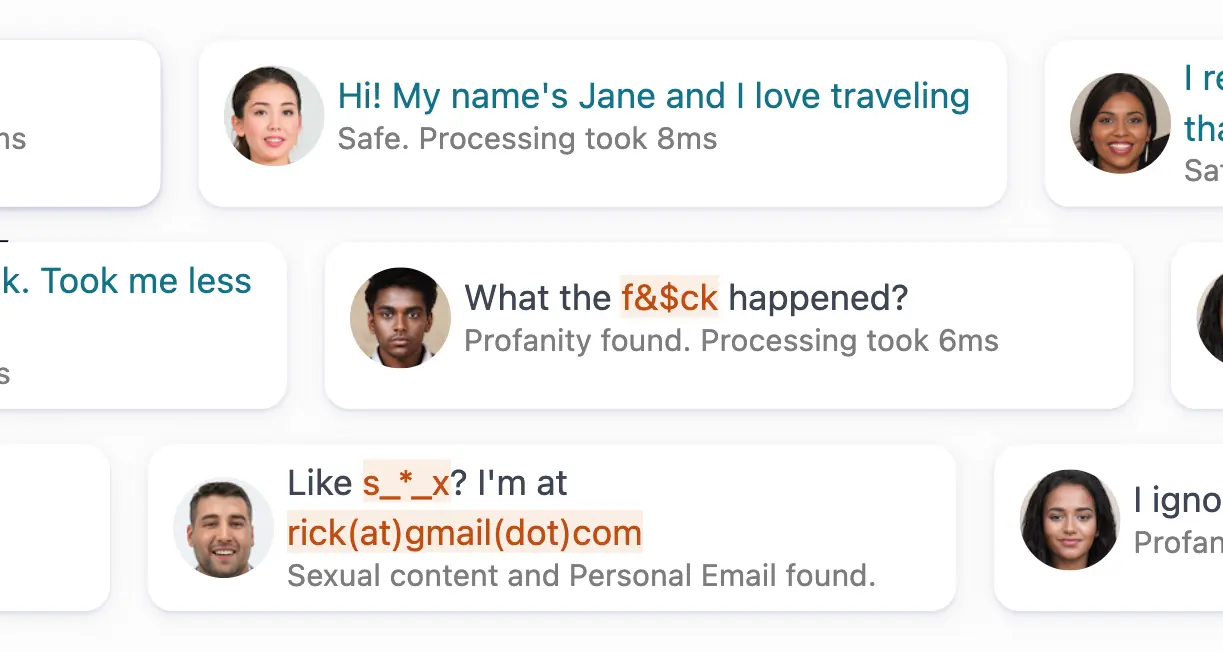
Automatically determine if an image was AI-generated or not. Assess the authenticity of media. Flag GenAI and deepfakes.
Explore AI DetectionStable Diffusion

Identify similar and duplicate content. Prevent spammy behavior. Create custom disallow lists to block abuse.
See Near Duplicate Detection
Detect abusive links, QR codes, phone numbers, email addresses or references to other platforms. Detect embedded contact information in images. Prevent phishing, extortion and circumvention attempts.
Sign upExternal username

Detect activities such as smoking, vaping, gambling, drinking alcohol. Detect sextoys, banknotes, coins...
Explore Models
Automatically detect low-quality images. Identify issues like bad framing, blurriness, and poor lighting. Highlight high-quality content efficiently.
Explore Quality DetectionExposure, framing & focus

Enhanced profile picture verification: check if the image contains a clear and recognizable face, if the face is real, if other people or children are present, etc.
Sign up
The API returns moderation results instantly and scales automatically to adapt to your needs.
Easily grow your Moderation Pipeline to tens of millions of images per month.
Built upon state-of-the-art models and proprietary technology. The moderation decisions are consistent and auditable, with feedback loops and continuous improvement built-in.
The API was built by developers for developers. You only need a few lines of code to be up and running.
Leverage our simple SDKs and detailed documentation.
No human moderator is involved, your images remain private and are not shared with any 3rd party.
« Sightengine can tell in milliseconds if a photograph counts as safe »
Empower your Business with powerful Multimodal Models. We power hundreds of platforms and apps worldwide.
SIGN UP NOW