Insults, personal and identity attacks — Content Moderation
Page contents
- Definitions: Insults and hate speech in user content
- What's at stake
- How to detect insults and hate speech
- What actions should be taken with insulting and hatred content
Definitions: Insults and hate speech in user content
Insulting or hate speech is a very broad topic as it includes various situations like:
- insults directed towards individuals and personal attacks, i.e. a form of speech deliberately intended to be rude and to attack a specific person
- insults directed towards public entities like a company or a public figure
- hate speech and identity attacks, i.e. speech that attacks or disparages a person or group of persons on the basis of protected characteristics such as sexual orientation / gender, origin / ethnicity / nationality, religion, skin color, disability but also physical appearance, social environment, language or age
Online attacks could be considered as violence or abuse. In its Hate Crime Report of 2021, Galop (a UK’s LGBT+ anti-abuse charity) indicated that among 523 people who have experienced abuse because of their gender or sexual orientation, 60% say that the abuse occurred online.
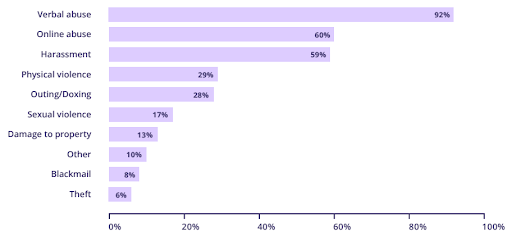 Type of anti-LGBT+ violence or abuse experienced by 523 people (Galop Hate Crime Report 2021)
Type of anti-LGBT+ violence or abuse experienced by 523 people (Galop Hate Crime Report 2021)
What's at stake
Defining this category is a challenge as it is not easy to define its boundaries: what should be considered as a legitimate opinion? What could be the subject of a debate between users? The answers to these questions really depend on the platform you want to build.
Because public entities such as politicians or companies often lead to heated debate between users and because freedom of expression generally prevails on big platforms and applications, social media sites typically allow content that criticizes businesses and politicians as long as it complies with their guidelines about hate speech, harassment, and other improper content.
More generally, below are some key points on why it is important to address the issue of personal and identity attacks.
Content inciting hatred or calling for violence against people or protected groups are often based on any of the following attributes: age, caste, disability, ethnicity, gender identity and expression, nationality, race, immigration status, religion, sex, sexual orientation, victims of a major violent event and their kin or veteran status.
Most user-generated texts that are considered hate speech express hateful ideas without naming a specific person and this is also often the case for insulting messages. But as Meta indicated in a 2017 post, such content could "feel very personal and, depending on someone's experiences, could even feel dangerous". This kind of comment therefore shouldn't be considered as a simple opinion.
There is mostly no legal obligation to detect insults and attacks but in some countries in the EU for example, it is illegal to encourage and promote hate. In addition, users of a platform or an application probably wouldn’t tolerate such content and might decide to leave the platform if no action is taken to handle the situation.
Finally, detecting insults and hate speech is one of the most common tasks in the text moderation field. There are more and more papers on this topic and especially on hate speech detection. This confirms that this topic should be detected as it is a very common issue for all platforms and applications.
How to detect insults and hate speech
Platforms could decide to automatically block comments containing insults or hate speech before they are sent. This is called preventive moderation. For example, Twitch uses AutoMod, a tool that "hold[s] risky messages from chat so they can be reviewed by a channel moderator before appearing to other viewers in the chat". If the message is actually against the policy, the user will get a notification or a pop-up screen indicating that its message can’t be sent.
If they don’t want to do preventive moderation, apps and platforms generally resort to four levels of detection measures:
- user reporting
- human moderators
- keyword-based filters
- ML models
User reporting
Platforms should consider the great help that other users can provide: they can report insults, attacks and hate speech to the trust and safety team so that these are reviewed by moderators and handled by the platform. It's a simple way to do text moderation, the user just needs a way to do the report. The main disadvantage is the delay needed to properly handle a potentially large volume of reports.
To simplify the handling of user reports and make the difference between the possible targets of the message, it is important that users have the option to categorize their reports, with categories such as targeted against an individual, targeted against a public figure or targeted against a company.
Human moderators
Human moderators can also help to detect potential insults and hate speech, but they should be provided with clear guidelines and training on the different ways someone could use to insult or attack an individual or a public entity:
- New insulting words or words expressing hate are often used by people, either to try to bypass the moderation system or because they become more popular and trendy.
- Users could use ambiguous or implicit words to insult or attack someone that are not always used in an insulting way.
A relevant and proper training should be done on a regular basis to stay up-to-date with these new forms of insults and hate speech and minimize the common issues of human moderation like the lack of speed and consistency.
Keyword-based filters
Keywords are a good way to pre-filter comments and messages by detecting all the words related to insults and hate speech such as:
- general insults and attacks (that could be directed towards individuals or public entities): idiot, sob, jerk, dumb, etc.
- hate speech and identity attacks including for example:
- sexual orientation / gender: faggot, batty boy, shemale, tranny, etc.
- origin / ethnicity: tacohead, gringo, paki, chink, towelhead, etc.
- religion: muzzie, ikey, mocky, etc.
- skin color: nigger, blacky, nig-nog, whithey, etc.
- disability: schizo, tard, deformed, window licker, etc.
- physical appearance: fatty, chopstick, beanpole, etc.
- social environment:
piss-poor, skint, stony-broke, peckerwood, etc.- political opinion:
leftist, fascist, etc.More examples of bad keywords can be found here for instance. Since users always find creative ways to develop new words to harass others, it is best to always research and develop new keywords to stay updated.
Keywords are helpful as human moderators can focus on a shorter sample of messages to be verified, leading to better reactivity. They are quite efficient to detect content related to personal or identity attacks but:
- They will still miss some offensive texts that do not contain any bad words:
- They will necessarily detect false positives, i.e. unproblematic texts such as reports of insults or hate speech, or bad words that are context-dependent, as they do not rely on the context:
 I really don’t understand how people can accept men loving men...
I really don’t understand how people can accept men loving men... Trans-women are not women and they should not compete against other women in certain sports.
Trans-women are not women and they should not compete against other women in certain sports. Muslims do not belong here!
Muslims do not belong here! He said I was an idiot!
He said I was an idiot! Using the word tard is really offensive.
Using the word tard is really offensive. We had a fat meal with a few friends.
We had a fat meal with a few friends.ML models
The use of ML models may complement the keywords and human moderators approach by detecting such cases with the help of annotated datasets containing insulting or hatred content.
Automated moderation can also be used to moderate images and videos submitted by users, and by detecting offensive symbols representing hateful ideas (nazi-era or supremacist symbols) as well as insulting gestures (middle finger).
What actions should be taken with insulting and hatred content
Detected insulting or hatred messages should be appropriately treated. When detecting such content, platforms and applications should first do a triage to make the difference between the possible targets of the message.
Attacks directed towards individuals and protected groups
When a hateful or insulting text is detected, platforms can use more or less severe sanctions depending on the case. This can range from simply removing the insulting text to suspending the account of the author of the text from the platform, for a limited time or permanently. For some extreme cases where insults or hate speech escalate to an actual threat, platforms could report them to the relevant local authorities. In its hateful conduct policy, Twitter also suggests the downranking and reduced visibility of the tweets violating the policy.
Several criteria should be taken into account when deciding on the sanction:
- Is the user already known for posting insulting and / or hateful content?
- Is the content clearly expressing a bad intention?
- Is it explicitly directed against a person?
- Is the level of toxicity of the text very high?
To answer this question, it would be interesting to set up a moderation log to allow all moderators to report any incidents encountered for a specific user. It would help to identify users who have previously used hateful language or insults.
If the content is ambiguous (for example if it has two meanings), it is more complicated to penalize a user.
Insulting or hateful content directed against a named individual may be considered a direct threat.
For example, wishing for the death of a community is probably more serious than making a bad / poor joke about that same community.
Attacks directed towards public figures or companies
Platforms detecting content criticizing public entities such as politicians or companies should make sure the content is respecting the community guidelines. Here are some examples of contents that are typically allowed:
- Opinions and comments on the actions or policies of a politician or corporation, or on any other public figure, as long as they are respectful and do not involve threats or personal attacks.
- News articles or reports that provide critical analysis or commentary on a politician's or company's actions or policies, or on any other public figure, as long as they are factual and not defamatory.
- Satirical content that pokes fun at a politician's or company's actions or policies, or at any other public figure, as long as it does not contain hate speech or other forms of inappropriate content.
- Memes or other forms of humorous content that criticize a politician's or company's actions or policies, or any other public figure, as long as they are not defamatory or do not contain hate speech.
- Protests and actions organized against a politician or a company, or against any other public figure, as long as they are not coordinate attacks to boycott or call for violence, whether the public entity belongs to a specific protected group or not.
Detected threats, insults, hate speech, defamatory content against public entities should be treated as personal attacks and attacks towards protected groups.
More generally, when building the rules of an online community, it is important to encourage positive behavior from users. In their advices to build a safe community, Discord says that setting an example as a community leader or practicing de-escalation by offering a second chance to a user who causes trouble are also solutions.
For automated detection solutions, explore Sightengine's text moderation API, our offensive and hate content detection for images, and our hate and offensive detection model documentation. See also our guide to keyword lists for text moderation, and our related guides on harassment and bullying and self-harm and mental health.
Read more

One Platform for AI Image, Video, and Audio Detection
Why multi-modal AI detection across images, video and audio in a single enterprise-ready platform eliminates blind spots and operational complexity.

Illegal traffic and trade — Content Moderation
This is a guide to detecting, moderating and handling illegal traffic and trade in texts and images.
Head back to the Knowledge Center
- social environment:
- sexual orientation / gender: