Text Moderation in Images/Videos
Deprecated text-contentDetect profanity, personally identifiable information (PII) such as email addresses and phone numbers, links and URLs in images and videos.
Overview
The Visual Text Moderation API is useful to determine if an image or video contains unwanted text such as profanity or personally identifiable information.
The API gives you fine-grained control over the moderation decision. The API will tell you what type of content has been found (phone number, email address, discriminatory content, sexual content...) along with a text extract of the content. You can then use this response to reject, flag or review the image/video on your end.
Just like our other Image Moderation APIs, this API uses advanced AI to perform the analysis entirely automatically. There are no humans reviewing your content. This helps us achieve very fast turnaround times — typically a few hundreds of milliseconds — and very high scalablity.

Principles
The Text Moderation API for Images works in several steps:
- Detection of text items contained in the image
- Recognition of the text (this is equivalent to transforming text into string objects)
- Analysis of the recognized text, through our rule-based text moderation engine
Use-cases
- Prevent users from adding insults, profanity, racial slurs or sexually suggestive text in an image
- Remove photos that contain PII such as an email address or phone number
- Flag users who include links/URLs in their images
- Prevent users from mentioning their social accounts in images
Use the OCR API to access the raw text content of the image or video.
Categories
The rules are grouped into categories, to help you implement custom filters based on the type of flagged content.
| Category | Description |
| profanity | The profanity category contains following types of terms and expressions:
|
| personal (pii) | The personal category contains following types of terms and expressions:
|
| link | URLs to external websites and pages. We can flag domains known to host unsafe or unwanted content read more |
| extremism | words, expressions or slogan related to extremist ideologies, people or events |
| weapon | names or terms that related to guns, rifles and firearms |
| medical | names related to medical drugs |
| drug | names related to recreational drugs |
| self-harm | terms related to suicide and self-inflected injuries |
| violence | expressions of violence such as kicking, punching or harming someone, or threatening to do so |
| spam | expressions commonly associated with spam or with circumvention, i.e. attempts to send or lure the user to another platform |
| content-trade | requests or messages encouraging users to send, exchange or sell photos or videos of themselves |
| money-transaction | requests or messages encouraging users to send money |
| blacklist (custom) | custom list of terms and expressions read more |
Profanity Detection in Images
Profanity Detection will enable you to detect insults, discriminatory content, sexual content or other inappropriate words and phrases in your images.
It is a lot stronger than word-based filters. It uses advanced language analysis to detect objectionable content, even when users specifically attempt to circumvent your filters. It covers obfuscation techniques such as repetitions, insertions, spelling mistakes, leet speak and more. Learn more on our Text Moderation Engine.
Personal Information Detection in Images
Email addresses
Email addresses will be detected and flagged as such in the image.

Phone numbers
Phone numbers will be detected and flagged as such in the image.
You can select the countries to be covered through the opt_countries parameter. Provide a comma-separated list of the ISO 3166 2-letter country codes. For instance us for the United-States, fr for France. See the full list of supported countries.
If you do not specify any country, the API will default to the following list of countries: United States us, France fr, United Kingdom gb

Link and URL Detection in Images
Links and URLs will be detected and flagged as such in the image.

In addition to detecting URLs in Images or Videos, you can also moderate the link to determine if the link is unsafe, deceptive or known to contain otherwise unwanted content (such as adult content, gambling, drugs...). More details are available on the URL and link moderation page.
Social Account Detection in Images
Mentions of social networks and social accounts can be detected in images. This detection works on any text-based mention. It will not flag logos of said social networks.
The most common social networks are supported by default: facebook, whatsapp, snapchat. instagram. Other social networks can be made available on a custom basis. Reach out for more.

Custom disallow or allow lists
You can use custom disallow lists (also known as blacklist or ban list) and allow lists along with with Text-in-image moderation and Text-in-video moderation.
To create a new text list, go to the dedicated page on your dashboard.
Once your text list has been created, you will have the opportunity to add entries to the text list.
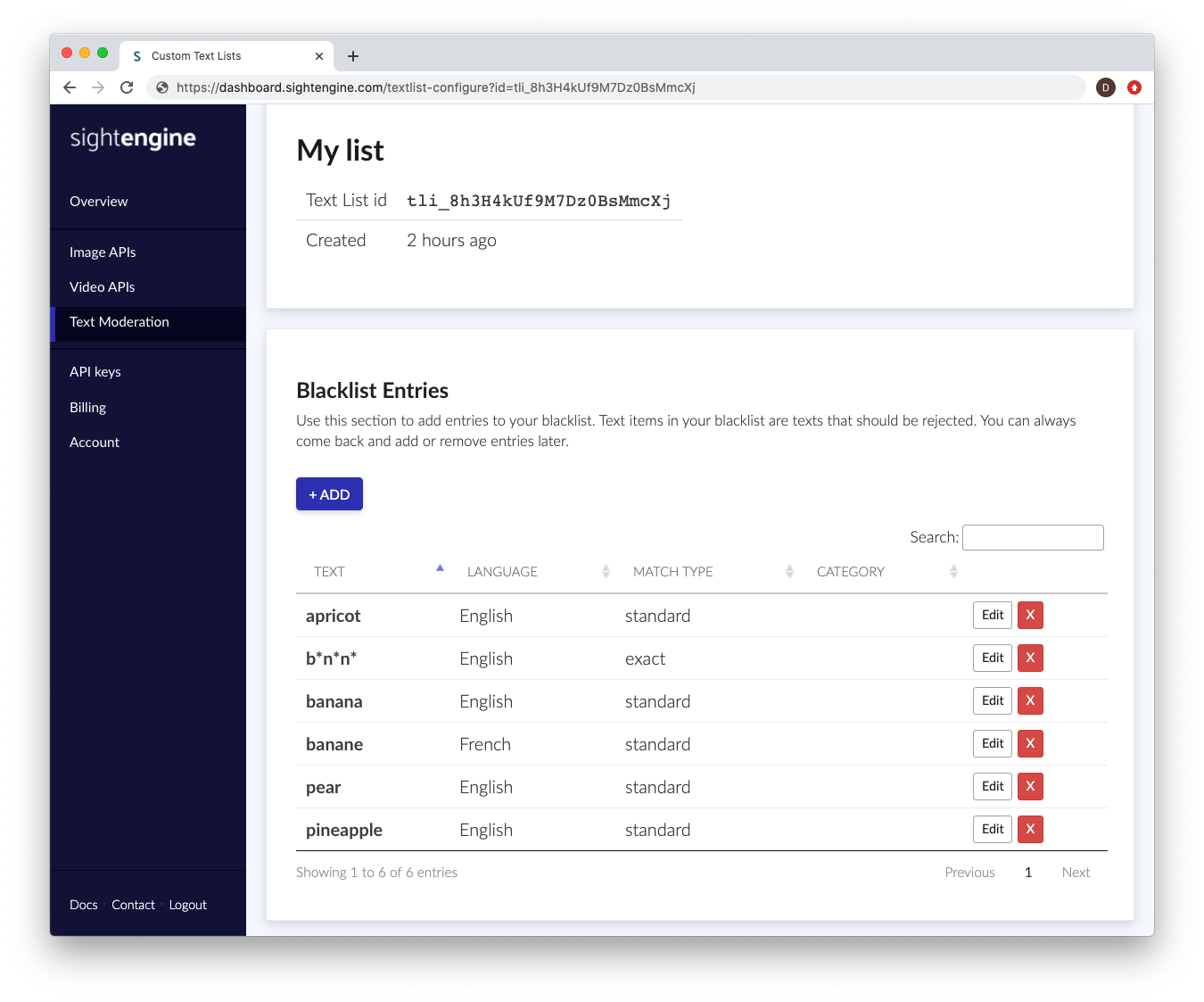
Each entry is a text item that you want to detect, along with meta-data to help our engine determine how and when this entry should be detected. The following information will be needed:
- Text: this is the text item you want to detect.
- Language: this is the language to which the text item applies. If it appears in a text item with a different language, it will not be flagged. If you need a text item to be detected in all languages, select all
- Match type: this is the way the detection engine should detect. Choose exact match if you want the engine to detect the exact string, with no modifications (apart from case modifications).
Choose standard match if you want the engine to detect variations such as phonetic variations, repetitions, typos, leet speak etc... This will typically cover millions of variations and make sure your users cannot simply obfuscate the word to fool the engine. - Category: this is a suggested categorization of the text item, to help you sort and filter entries.
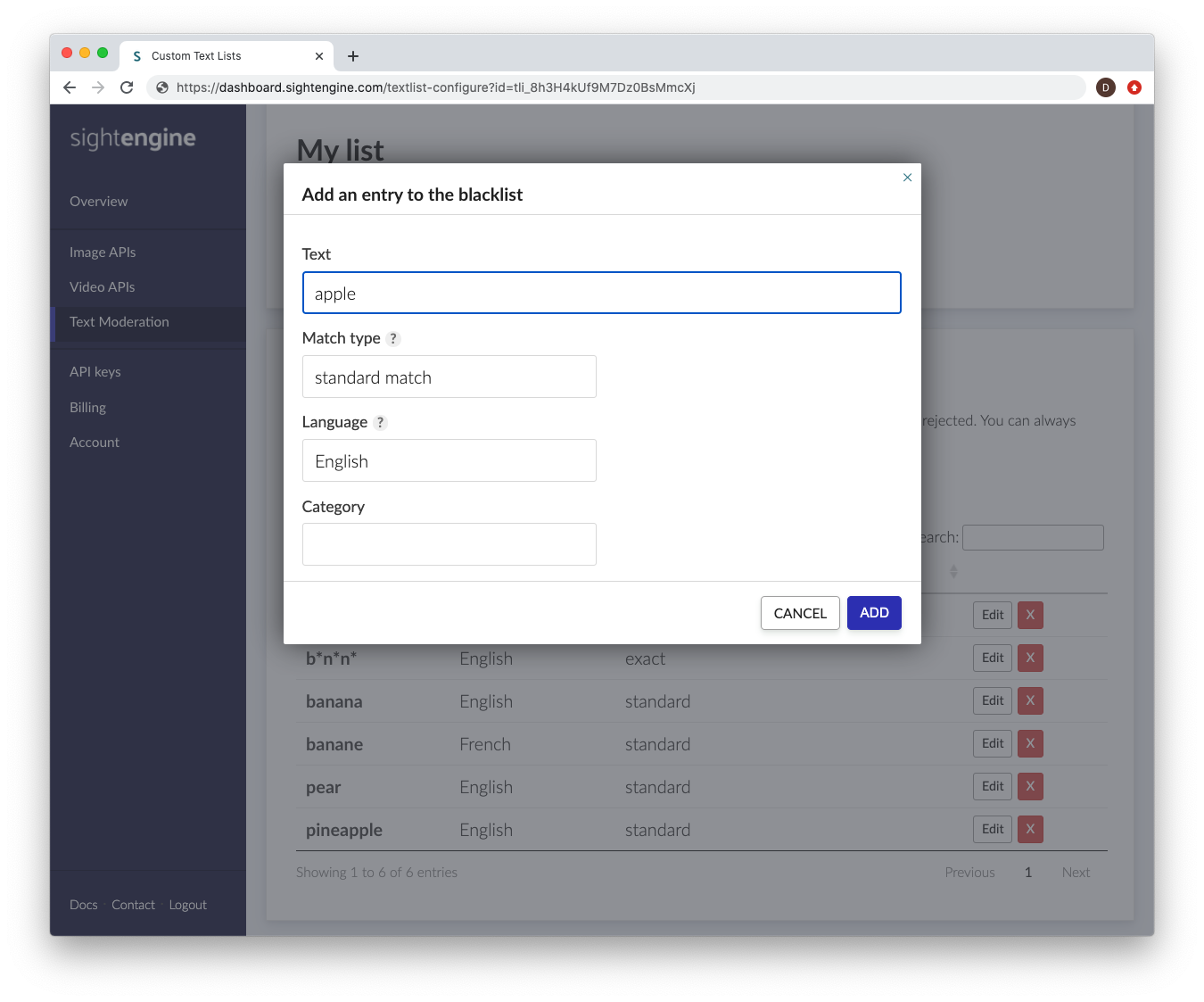
While most users only need to create a single text list, you can create multiple text lists to apply different moderation criteria to different types of text items.
In order to use a custom list, you will have to specify the corresponding id of the list in the opt_textlist parameter in your API calls.
Languages
English is the default language used for the text recognition and profanity filtering.
You can set a different language with the opt_lang parameter. To do so use the following codes:
| Language | Code |
| English (default) | en |
| Chinese | zh |
| Danish | da |
| Dutch | nl |
| Finnish | fi |
| French | fr |
| German | de |
| Italian | it |
| Korean | ko |
| Norwegian | no |
| Polish | pl |
| Portuguese | pt |
| Romanian | ro |
| Russian | ru |
| Spanish | es |
| Swedish | sv |
| Tagalog / Filipino | tl |
| Turkish | tr |
Other languages are available upon request. Please get in touch.
Use the model (images)
If you haven't already, create an account to get your own API keys.
Moderate text in images
Let's say you want to moderate the following image:
You can either share a URL to the image, or upload the image file. Supported formats include JPEG, PNG, WebP, AVIF and more.
Option 1: Send image URL
Here's how to proceed if you choose to share the image URL:
curl -X GET -G 'https://api.sightengine.com/1.0/check.json' \
-d 'models=text-content' \
-d 'text_categories=sexual,insult,inappropriate,discriminatory,phone_number,email' \
-d 'opt_lang=en,fr,es,de' \
-d 'opt_countries=us,gb,fr,de' \
-d 'api_user={api_user}&api_secret={api_secret}' \
--data-urlencode 'url=https://sightengine.com/assets/img/examples/example-text-ocr-3.jpg'
# this example uses requests
import requests
import json
params = {
'url': 'https://sightengine.com/assets/img/examples/example-text-ocr-3.jpg',
'models': 'text-content',
'text_categories': 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang': 'en,fr,es,de',
'opt_countries': 'us,gb,fr,de',
'api_user': '{api_user}',
'api_secret': '{api_secret}'
}
r = requests.get('https://api.sightengine.com/1.0/check.json', params=params)
output = json.loads(r.text)
$params = array(
'url' => 'https://sightengine.com/assets/img/examples/example-text-ocr-3.jpg',
'models' => 'text-content',
'text_categories' => 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang' => 'en,fr,es,de',
'opt_countries' => 'us,gb,fr,de',
'api_user' => '{api_user}',
'api_secret' => '{api_secret}',
);
// this example uses cURL
$ch = curl_init('https://api.sightengine.com/1.0/check.json?'.http_build_query($params));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
$output = json_decode($response, true);
// this example uses axios
const axios = require('axios');
axios.get('https://api.sightengine.com/1.0/check.json', {
params: {
'url': 'https://sightengine.com/assets/img/examples/example-text-ocr-3.jpg',
'models': 'text-content',
'text_categories': 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang': 'en,fr,es,de',
'opt_countries': 'us,gb,fr,de',
'api_user': '{api_user}',
'api_secret': '{api_secret}',
}
})
.then(function (response) {
// on success: handle response
console.log(response.data);
})
.catch(function (error) {
// handle error
if (error.response) console.log(error.response.data);
else console.log(error.message);
});
See request parameter description
| Parameter | Type | Description |
| url | string | URL of the image to analyze |
| models | string | comma-separated list of models to apply |
| text_categories | string | comma-separated list of moderation categories |
| opt_lang | string | comma-separated list of target languages (optional) |
| opt_countries | string | comma-separated list of target countries for phone number detection (optional) |
| opt_textlist | string | id of a custom list (disallow or allow list) (optional) |
| api_user | string | your API user id |
| api_secret | string | your API secret |
Option 2: Send image file
Here's how to proceed if you choose to upload the image file:
curl -X POST 'https://api.sightengine.com/1.0/check.json' \
-F 'media=@/path/to/image.jpg' \
-F 'models=text-content' \
-F 'text_categories=sexual,insult,inappropriate,discriminatory,phone_number,email' \
-F 'opt_lang=en,fr,es,de' \
-F 'opt_countries=us,gb,fr,de' \
-F 'api_user={api_user}' \
-F 'api_secret={api_secret}'
# this example uses requests
import requests
import json
params = {
'models': 'text-content',
'text_categories': 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang': 'en,fr,es,de',
'opt_countries': 'us,gb,fr,de',
'api_user': '{api_user}',
'api_secret': '{api_secret}'
}
files = {'media': open('/path/to/image.jpg', 'rb')}
r = requests.post('https://api.sightengine.com/1.0/check.json', files=files, data=params)
output = json.loads(r.text)
$params = array(
'media' => new CurlFile('/path/to/image.jpg'),
'models' => 'text-content',
'text_categories' => 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang' => 'en,fr,es,de',
'opt_countries' => 'us,gb,fr,de',
'api_user' => '{api_user}',
'api_secret' => '{api_secret}',
);
// this example uses cURL
$ch = curl_init('https://api.sightengine.com/1.0/check.json');
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
$response = curl_exec($ch);
curl_close($ch);
$output = json_decode($response, true);
// this example uses axios and form-data
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
data = new FormData();
data.append('media', fs.createReadStream('/path/to/image.jpg'));
data.append('models', 'text-content');
data.append('text_categories', 'sexual,insult,inappropriate,discriminatory,phone_number,email');
data.append('opt_lang', 'en,fr,es,de');
data.append('opt_countries', 'us,gb,fr,de');
data.append('api_user', '{api_user}');
data.append('api_secret', '{api_secret}');
axios({
method: 'post',
url:'https://api.sightengine.com/1.0/check.json',
data: data,
headers: data.getHeaders()
})
.then(function (response) {
// on success: handle response
console.log(response.data);
})
.catch(function (error) {
// handle error
if (error.response) console.log(error.response.data);
else console.log(error.message);
});
See request parameter description
| Parameter | Type | Description |
| media | file | image to analyze |
| models | string | comma-separated list of models to apply |
| text_categories | string | comma-separated list of moderation categories |
| opt_lang | string | comma-separated list of target languages (optional) |
| opt_countries | string | comma-separated list of target countries for phone number detection (optional) |
| opt_textlist | string | id of a custom list (disallow or allow list) (optional) |
| api_user | string | your API user id |
| api_secret | string | your API secret |
API response
The API will then return a JSON response with the following structure:
{
"status": "success",
"request": {
"id": "req_22Qd0gUNmRH4GCYLvYtN6",
"timestamp": 1512483673.1405,
"operations": 1
},
"text": {
"profanity": [],
"personal": [
{
"type": "phone_number_us",
"match": "+1 800 222 2408"
}
],
"link": [],
"social": [],
"extremism": [],
"medical": [],
"drug": [],
"weapon": [],
"content-trade": [],
"money-transaction": [],
"spam": [],
"violence": [],
"self-harm": [],
"ignored_text": false
},
"media": {
"id": "med_22Qdfb5s97w8EDuY7Yfjp",
"uri": "https://sightengine.com/assets/img/examples/example-text-ocr-3.jpg"
}
}
Successful Response
Status code: 200, Content-Type: application/json| Field | Type | Description |
| status | string | status of the request, either "success" or "failure" |
| request | object | information about the processed request |
| request.id | string | unique identifier of the request |
| request.timestamp | float | timestamp of the request in Unix time |
| request.operations | integer | number of operations consumed by the request |
| text | object | results for the model |
| media | object | information about the media analyzed |
| media.id | string | unique identifier of the media |
| media.uri | string | URI of the media analyzed: either the URL or the filename |
Error
Status codes: 4xx and 5xx. See how error responses are structured.Use the model (videos)
Moderate text in videos
Option 1: Short video
Here's how to proceed to analyze a short video (less than 1 minute):
curl -X POST 'https://api.sightengine.com/1.0/video/check-sync.json' \
-F 'media=@/path/to/video.mp4' \
-F 'models=text-content' \
-F 'text_categories=sexual,insult,inappropriate,discriminatory,phone_number,email' \
-F 'opt_lang=en,fr,es,de' \
-F 'opt_countries=us,gb,fr,de' \
-F 'api_user={api_user}' \
-F 'api_secret={api_secret}'
# this example uses requests
import requests
import json
params = {
# specify the models you want to apply
'models': 'text-content',
'text_categories': 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang': 'en,fr,es,de',
'opt_countries': 'us,gb,fr,de',
'api_user': '{api_user}',
'api_secret': '{api_secret}'
}
files = {'media': open('/path/to/video.mp4', 'rb')}
r = requests.post('https://api.sightengine.com/1.0/video/check-sync.json', files=files, data=params)
output = json.loads(r.text)
$params = array(
'media' => new CurlFile('/path/to/video.mp4'),
// specify the models you want to apply
'models' => 'text-content',
'text_categories' => 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang' => 'en,fr,es,de',
'opt_countries' => 'us,gb,fr,de',
'api_user' => '{api_user}',
'api_secret' => '{api_secret}',
);
// this example uses cURL
$ch = curl_init('https://api.sightengine.com/1.0/video/check-sync.json');
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
$response = curl_exec($ch);
curl_close($ch);
$output = json_decode($response, true);
// this example uses axios and form-data
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
data = new FormData();
data.append('media', fs.createReadStream('/path/to/video.mp4'));
// specify the models you want to apply
data.append('models', 'text-content');
data.append('text_categories', 'sexual,insult,inappropriate,discriminatory,phone_number,email');
data.append('opt_lang', 'en,fr,es,de');
data.append('opt_countries', 'us,gb,fr,de');
data.append('api_user', '{api_user}');
data.append('api_secret', '{api_secret}');
axios({
method: 'post',
url:'https://api.sightengine.com/1.0/video/check-sync.json',
data: data,
headers: data.getHeaders()
})
.then(function (response) {
// on success: handle response
console.log(response.data);
})
.catch(function (error) {
// handle error
if (error.response) console.log(error.response.data);
else console.log(error.message);
});
See request parameter description
| Parameter | Type | Description |
| media | file | image to analyze |
| models | string | comma-separated list of models to apply |
| interval | float | frame interval in seconds, out of 0.5, 1, 2, 3, 4, 5 (optional) |
| api_user | string | your API user id |
| api_secret | string | your API secret |
Option 2: Long video
Here's how to proceed to analyze a long video. Note that if the video file is very large, you might first need to upload it through the Upload API.
curl -X POST 'https://api.sightengine.com/1.0/video/check.json' \
-F 'media=@/path/to/video.mp4' \
-F 'models=text-content' \
-F 'callback_url=https://yourcallback/path' \
-F 'text_categories=sexual,insult,inappropriate,discriminatory,phone_number,email' \
-F 'opt_lang=en,fr,es,de' \
-F 'opt_countries=us,gb,fr,de' \
-F 'api_user={api_user}' \
-F 'api_secret={api_secret}'
# this example uses requests
import requests
import json
params = {
# specify the models you want to apply
'models': 'text-content',
# specify where you want to receive result callbacks
'callback_url': 'https://yourcallback/path',
'text_categories': 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang': 'en,fr,es,de',
'opt_countries': 'us,gb,fr,de',
'api_user': '{api_user}',
'api_secret': '{api_secret}'
}
files = {'media': open('/path/to/video.mp4', 'rb')}
r = requests.post('https://api.sightengine.com/1.0/video/check.json', files=files, data=params)
output = json.loads(r.text)
$params = array(
'media' => new CurlFile('/path/to/video.mp4'),
// specify the models you want to apply
'models' => 'text-content',
// specify where you want to receive result callbacks
'callback_url' => 'https://yourcallback/path',
'text_categories' => 'sexual,insult,inappropriate,discriminatory,phone_number,email',
'opt_lang' => 'en,fr,es,de',
'opt_countries' => 'us,gb,fr,de',
'api_user' => '{api_user}',
'api_secret' => '{api_secret}',
);
// this example uses cURL
$ch = curl_init('https://api.sightengine.com/1.0/video/check.json');
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
$response = curl_exec($ch);
curl_close($ch);
$output = json_decode($response, true);
// this example uses axios and form-data
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
data = new FormData();
data.append('media', fs.createReadStream('/path/to/video.mp4'));
// specify the models you want to apply
data.append('models', 'text-content');
// specify where you want to receive result callbacks
data.append('callback_url', 'https://yourcallback/path');
data.append('text_categories', 'sexual,insult,inappropriate,discriminatory,phone_number,email');
data.append('opt_lang', 'en,fr,es,de');
data.append('opt_countries', 'us,gb,fr,de');
data.append('api_user', '{api_user}');
data.append('api_secret', '{api_secret}');
axios({
method: 'post',
url:'https://api.sightengine.com/1.0/video/check.json',
data: data,
headers: data.getHeaders()
})
.then(function (response) {
// on success: handle response
console.log(response.data);
})
.catch(function (error) {
// handle error
if (error.response) console.log(error.response.data);
else console.log(error.message);
});
See request parameter description
| Parameter | Type | Description |
| media | file | image to analyze |
| callback_url | string | callback URL to receive moderation updates (optional) |
| models | string | comma-separated list of models to apply |
| interval | float | frame interval in seconds, out of 0.5, 1, 2, 3, 4, 5 (optional) |
| api_user | string | your API user id |
| api_secret | string | your API secret |
Option 3: Live-stream
Here's how to proceed to analyze a live-stream:
curl -X GET -G 'https://api.sightengine.com/1.0/video/check.json' \
--data-urlencode 'stream_url=https://domain.tld/path/video.m3u8' \
-d 'models=text-content' \
-d 'callback_url=https://your.callback.url/path' \
-d 'api_user={api_user}' \
-d 'api_secret={api_secret}'
# this example uses requests
import requests
import json
params = {
'stream_url': 'https://domain.tld/path/video.m3u8',
# specify the models you want to apply
'models': 'text-content',
# specify where you want to receive result callbacks
'callback_url': 'https://your.callback.url/path',
'api_user': '{api_user}',
'api_secret': '{api_secret}'
}
r = requests.post('https://api.sightengine.com/1.0/video/check.json', data=params)
output = json.loads(r.text)
$params = array(
'stream_url' => 'https://domain.tld/path/video.m3u8',
// specify the models you want to apply
'models' => 'text-content',
// specify where you want to receive result callbacks
'callback_url' => 'https://your.callback.url/path',
'api_user' => '{api_user}',
'api_secret' => '{api_secret}',
);
// this example uses cURL
$ch = curl_init('https://api.sightengine.com/1.0/video/check.json');
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
$response = curl_exec($ch);
curl_close($ch);
$output = json_decode($response, true);
// this example uses axios and form-data
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
data = new FormData();
data.append('stream_url', 'https://domain.tld/path/video.m3u8');
// specify the models you want to apply
data.append('models', 'text-content');
// specify where you want to receive result callbacks
data.append('callback_url', 'https://your.callback.url/path');
data.append('api_user', '{api_user}');
data.append('api_secret', '{api_secret}');
axios({
method: 'post',
url:'https://api.sightengine.com/1.0/video/check.json',
data: data,
headers: data.getHeaders()
})
.then(function (response) {
// on success: handle response
console.log(response.data);
})
.catch(function (error) {
// handle error
if (error.response) console.log(error.response.data);
else console.log(error.message);
});
See request parameter description
| Parameter | Type | Description |
| stream_url | string | URL of the video stream |
| callback_url | string | callback URL to receive moderation updates (optional) |
| models | string | comma-separated list of models to apply |
| interval | float | frame interval in seconds, out of 0.5, 1, 2, 3, 4, 5 (optional) |
| api_user | string | your API user id |
| api_secret | string | your API secret |
Moderation result
The Moderation result will be provided either directly in the request response (for sync calls, see below) or through the callback URL your provided (for async calls).
Here is the structure of the JSON response with moderation results for each analyzed frame under the data.frames array:
{
"status": "success",
"request": {
"id": "req_gmgHNy8oP6nvXYaJVLq9n",
"timestamp": 1717159864.348989,
"operations": 21
},
"data": {
"frames": [
{
"info": {
"id": "med_gmgHcUOwe41rWmqwPhVNU_1",
"position": 0
},
"text": {
"profanity": [],
"personal": [],
"link": [],
"social": [],
"extremism": [],
"medical": [],
"drug": [],
"weapon": [],
"content-trade": [],
"money-transaction": [],
"spam": [],
"violence": [],
"self-harm": [],
"ignored_text": false
},
},
...
]
},
"media": {
"id": "med_gmgHcUOwe41rWmqwPhVNU",
"uri": "yourfile.mp4"
},
}
You can use the classes under the text object to analyze text content in the video.